Fearless concurrency at a discount?
Hello! 👋🏽 Welcome to the first proper issue of PL Papers You Might Love. Today, I'll be taking a look at A Flexible Type System for Fearless Concurrency (PLDI 2022) by Mae Milano, Joshua Turcotti, and Andrew C. Myers (paper PDF).
Background
Over the past decade or so, Rust has popularized the notion of "fearless concurrency." The Rust compiler prevents data races1 at compile-time by maintaining an ownership-and-borrowing system that is integrated with its type system. In doing so, Rust has carved out a niche of its own amongst mainstream languages:2
- Data races are possible, anything can happen in the presence of a data race: Go, C++.
- Data races are possible, try to have "reasonable" behavior in the presence of data races: Java, Multicore OCaml.
- Data races are prevented at compile-time: safe Rust, and more recently Swift (with full safety-checking).
However, safety isn't free in terms of cognitive cost. Certain programs that are very easy to write in a language like Java become very hard or impossible to write in safe Rust. If you've tried to implement any tricky pointer-based data structures in Rust, or you've read Learn Rust With Entirely Too Many Linked Lists, you're probably nodding along in agreement. There are workarounds for this, such as using integer indices and/or unsafe Rust, but neither of those are very satisfying:
- Indices can suffer from the same problems as pointers (such as use-after-free), the main improvement is that there is no memory unsafety.
- Unsafe Rust doesn't catch data races at compile-time. It can also be hard to write, even for experienced programmers. There is ongoing work on improve ergonomics in this area (e.g. the MIRI checker).
In academia, there has been a bunch of work related to separation logic and linear types which also achieves data-race-freedom. However, such type systems are often hard-to-use, requiring many annotations. Or they can require manually converting your code to CPS, which is often undesirable for various reasons.
What this paper covers
In A Flexible Type System for Fearless Concurrency, the authors design a new type system that:
- Is region-based: enforcing a tree of regions rather than a tree of objects.3
- Prevents data races at compile-time while maintaining low annotation overhead.
- Supports familiar programming patterns, such as cyclic pointer-based structures using mutation, with small adjustments.
- Uses a special
if disconnectedprimitive that dynamically determines if a region can be safely split, by proving that the object graphs reachable from two references are mutually disjoint.
They also provide a proof of correctness and a type checker implementation.4
Key terminology
- reservation: The part of the heap accessible to a given thread. The type system ensures that different threads have disjoint reservations.
- region: A compile-time construct that groups objects which enter a thread's reservation as a unit. The program's object graph is partitioned into regions. A thread's reservation may have many regions.
- domination: Graph domination as applied to the object graph.
- transitively dominating references: References which lie on all paths from the root of the object graph to all objects transitively reachable from that reference.
- isolated (
iso): Qualifier for object fields intended to contain transitively dominating references. - global domination: A program property under which all isolated fields contain transitively dominating references.
- tempered domination: A program property under which some isolated fields do not contain transitively dominating references. In such a situation, these isolated fields are explicitly tracked by the type system with a "focus" mechanism.
Circular doubly-linked list example
Instead of going through the details of the paper, I think it is useful to walk through one of the fun code examples they showcase. I've added explicit return keywords for clarity as well as a bunch of inline comments.
// A circular doubly-linked list with 1 or more elements.
struct dll_node {
iso payload : data;
next : dll_node; // note: structs are reference types
prev : dll_node;
}
// A circular doubly-linked list with 0 or more elements.
struct dll {
iso hd : dll_node? // using the built-in optional type '?'
}
// Get the payload from the tail if the list is non-empty.
def remove_tail(l : dll) : data? {
let some(hd) = l.hd in { // non-empty case
let tail = hd.prev;
// rewire tail's predecessor and successor
tail.prev.next = hd; hd.prev = tail.prev;
// disconnect tail's object graph from rest of linked list
// to ensure disjointness for if disconnected
tail.next = tail; tail.prev = tail;
// `if disconnected` is a built-in operation that checks if
// two object graphs pointed to by the arguments do not overlap
if disconnected(tail, hd) {
l.hd = some(hd); // l.hd invalid at branch start
return some(tail.payload)
} else { // single-element case
l.hd = none;
return some(hd.payload)
}
} else { return none } // list was empty
}
My first thought on reading this was: it's kinda' amazing that circular doubly-linked lists can be made to work with code that largely looks like a typical imperative language.
That said, I also had a couple of immediate questions:
- Efficiency of
if disconnected: It's not clear how expensiveif disconnectedis. Naively, it seems like it would be awful in the general case. - Reference invalidation on
if disconnected: It's not super clear what is going on with the "l.hdinvalid at branch start" aspect, and if the type system can be tweaked to avoid having to do such seemingly-redundant assignments.
Let's discuss each of those.
Efficiency of if disconnected
This point is discussed in Section 5.2 Efficiently Checking Mutual Disconnection. It's a little complicated, so I've tried to explain it here in my own words below.5
- Recall from the definition of "tempered domination" that an
isoreference is transitively dominating if and only if it is not explicitly tracked by the type system. - Suppose there is a region
Rfor which allisoreferences contain transitively dominating references, and supposeRcontains two iso referencesAandBwhich transitively dominate object graphsOAandOBrespectively. IfOAandOBintersect, it must be the case thatOAcontainsBandOBcontainsA(by the definition of transitively dominating references). Conversely, ifOAdoes not containB, then it cannot intersect withOB. So it is sufficient to stop checking for the intersection of object graphs at transitively dominatingisoreferences. - The authors state that the typing rule for
if disconnected"ensures that its arguments come from the same region, and that nothing within that region is tracked".
These three points taken together imply that if disconnected can get away with checking object graph intersection only "up to" iso references. As far as I can tell, that's the core idea behind making this check efficient.
There is a second part about reference counts too.
We implemented a version of the if disconnected check that is efficient based on two usage assumptions. The first assumption is that data structure designers prefer to keep regions small when possible, placing the
isokeyword at abstraction boundaries—for example, collections place their contents inisofields [..]. The second assumption is thatif disconnectedis commonly used to detach a small portion of a region—often as small as a single object.Following these assumptions, we propose a two-step pro- cess for the efficient implementation of
if disconnected. First, store a reference count which tracks immediate heap references stored in non-isofields of structures. This stored reference count is updated only on field assignment, and does not need to be modified—or checked—on assignment to local variables, function invocation, or at any other time. Thus, it is lighter-weight than conventional reference counts.Second, the
if disconnectedcheck itself is implemented via interleaved traversals of the object graphs rooted by its two arguments, ignoring references which point outside the current region, and stopping when the smaller of the two has been fully explored (or a point of intersection has been found). During this traversal, the algorithm counts the number of times it has encountered each object, assembling a traversal reference count. At the end of the traversal, it compares this traversal reference count with the stored reference count, concluding that the object graphs are disconnected if the counts match, and conservatively assuming that they remain connected if the counts do not match.
At a high level, the aspect about comparing counts instead of actual object graphs makes sense from an efficiency perspective. However, I don't fully understand the details. Specifically, based on the "conservatively assuming" point, it seems like the proposed algorithm cannot definitively answer if two object graphs are certainly connected, it can only answer that they might be connected. If I'm understanding that right, it's not clear why this that is sufficient for writing code correctly.
Reference invalidation on if disconnected
Copying the point from before:
It's not super clear what is going on with the "
l.hdinvalid at branch start" aspect, and if the type system can be tweaked to avoid having to do such seemingly-redundant assignments.
I skimmed through parts of the type system description, but I still don't fully understand this one. I'm describing my intuition below based on one of their diagrams (the diagram is slightly out-of-sync with the code, with head instead of hd):
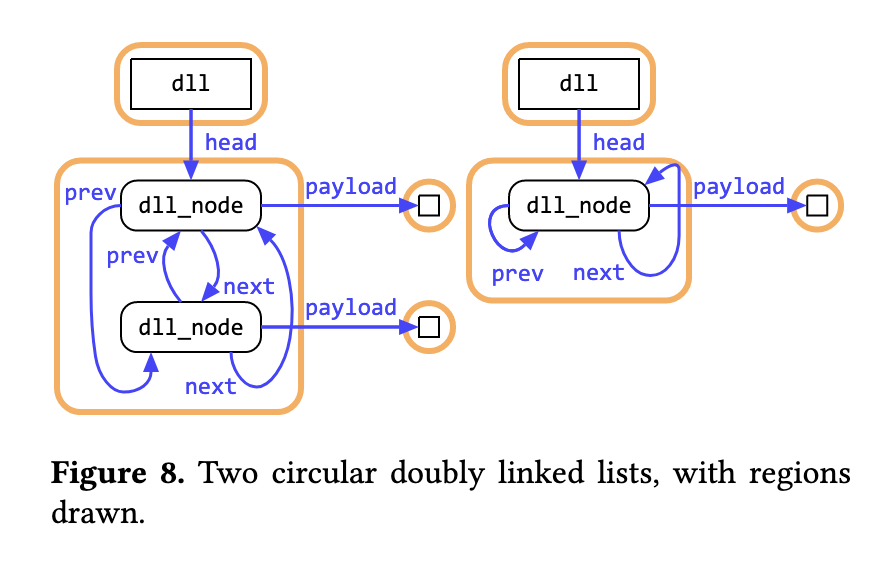
let some(hd) = l.hd in {
let tail = hd.prev;
// rewire tail's successor and predecessor
tail.prev.next = hd; hd.prev = tail.prev;
// disconnect tail's object graph to ensure disjointness
tail.next = tail; tail.prev = tail;
if disconnected(tail, hd) {
l.hd = some(hd); // l.hd invalid at branch start
return some(tail.payload)
} else // ...
} else // ...
The l.hd field points within the same region which includes hd and tail -- this fact is understood by the type system. In the true branch for if disconnected(tail, hd), the original region is split into two regions, but the type system can't know which of those two regions l.hd points to. (In this specific case, it might seem a little silly since the last use was if some(hd) = l.hd, but it doesn't seem resolvable in the general case.) So l.hd is "invalid" and needs to be restored to a valid state before the function returns.
Based on this, it seems like reference invalidation/re-assigment is fundamental to the design of if disconnected. Perhaps you could add some special-casing for specific situations, but you couldn't get rid of this "problem" in the general case.
OK! That was just one code example. The paper covers a lot more things; you're free to read it if you find it interesting. For example, some fun stuff that I didn't cover here:
- The
sendandrecvprimitives for concurrency. - Tempered domination and how the "focus" mechanism works.
- Support for same-region constraints using
~. (Pro tip: Check the appendix for some amazing function signatures.)
Details of the paper aside, here are some rough thoughts on adoption etc.
Potential risks to adoption
Interaction with polymorphism
The authors mention this as one of their assumptions:
data structure designers prefer to keep regions small when possible, placing the
isokeyword at abstraction boundaries—for example, collections place their contents inisofields
At face value, this seems reasonable. However, it's not clear to me how this affects composing collections.
As a somewhat contrived example, say you want to stash the nodes of a doubly-linked list in a tree, and the tree nodes store contents within an iso field. Is that even possible?
Based on my understanding so far, that wouldn't be possible, because the iso field would no longer be a transitively dominating reference. Sure, you could temporarily break this by having the type system track the iso fields for a few tree nodes, but it seems like this wouldn't be possible for an entire tree (unless you had some fancy type shenanigans).
Contrived example aside, it's not clear to me how often this problem would come up in practice. What happens if you have a bunch of domain-specific types which contain references, and you try putting those in containers with iso-content nodes... are there common situations where you'd run into issues?
Cognitive burden in practice
Based on the examples, it does seem like writing code in such a language would impose less mental and annotation overhead compared to something like Rust. It seems like the tradeoff is that using such a language is that it requires more thorough thinking about object graph connectivity, whereas Rust has what is arguably a simpler mantra: "mutation xor aliasing."
That said, I concede that I am biased here to some extent: I've written a fair amount of Rust code, whereas I don't really have experience writing code in this paper's language.
if disconnected misuse
One potential thing that can go wrong is that programmers may overuse if disconnected to avoid reasoning about object graphs. Or they may use it in ways where the runtime cost is not small when things go wrong. For example, trying to write a GUI library where the graph of widgets is a spaghetti ball of mutability might be possible, but it's probably still a bad idea.
Slow type-checking
One of the things I didn't discuss is the point about "Virtual Transformations" in the paper. The authors point out:
An astute reader may note that, unlike the initial typing rules in figure 10, TS1-Virtual-Transformation-Structural is not syntax-directed. We present a decision procedure for type checking with virtual transformations. It runs in common-case polynomial and worst-case exponential time.
[...]
We note however that, due to our choice to limit typeable
isofield accesses to only fields of currently declared variables, the number of H contexts reachable by virtual transformation is bounded above by the number of variables currently in scope. Thus, even a naive search suffices to obtain completeness, at the cost of run time exponential in the number of variables and the length of the longest function. Heuristics for speeding up search are briefly discussed in section 5.1.
In Section 5.1, they write:
By employing liveness analysis of variables and isolated fields as a unification oracle, our checker can verify our largest examples in a handful of seconds. When necessary, our tool still falls back to search. Other approaches—such as user annotations or an external constraint solver—may be useful for pathological cases. More details appear in the appendix.
For a production type-checker, "a handful of seconds" is quite a long time. I don't have a good sense for how much these pathological examples will matter in practice. For example, Algorithm W has bad worst-case time complexity, but it works quite well in practice on typical ML code.
If you're going to be implementing this (or a similar) type system, it seems like tackling this challenge early on is probably a good idea, to figure out if it is a deal-breaker or not in practice.
Closing thoughts
I think this paper presents a promising avenue for supporting "fearless concurrency" in application languages, especially implementations with tracing GCs.6
Some follow-ups I'd be interested in seeing:
- A comparison between this language's type system vs the current state of Project Verona.
- An implementation with an interpreter, so that one can play around with non-trivial examples, especially those involving concurrency.
That's it for now! This issue was sent to 57 subscribers. If you're interested in getting the next issue in your inbox directly, enter your email below. :) In the next issue, I will be covering Stabilizer: Statistically Sound Performance Evaluation (ASPLOS 2013) by Charlie Curtsinger and Emery Berger.
-
A couple of reasons for why you might want to prevent data races altogether:
- data races in the presence of unboxed types with mutability can lead to "object tearing," where different parts of a multi-word object are in a mutually inconsistent state due to missing synchronization.
- dynamic race detectors are usually not cheap enough to be always on (and if they are, they miss a large % of data races).
-
There are also many not-yet-mainstream-but-growing languages in this space, such as Pony, Carp, Vale and Cone. ↩
-
In this, it is similar to Microsoft's Project Verona rather than Rust. ↩
-
I don't know if the code is available in a more easily consumable form, such as on GitHub, but it's available on Zenodo as a compressed archive. ↩
-
The reasoning here seems a bit subtle, so I hope I didn't make any mistakes or misunderstand the paper. Please let me know if that's the case. ↩
-
Recall that the
if disconnectedcheck requires some cooperation with the memory management subsystem. RC-based language implementations and C/C++/Rust often rely on justmalloc/freefrom the system directly. ↩